
[latexpage]
Linear classifiers (Lesson 3) VS 2-layers-NN (Lesson 5): a visual viewpoint
Linear models are arguably one of the simplest approaches within the ML practitioner’s toolbox. Given an input x, the model boils down to f(x, W) = Wx + b. In case of CV, if we take the CIFAR10 dataset, x is an image and the pipeline looks like this:

Such a model can be interpreted in a few ways. Probably the most intuitive is the algebraic one, where the image’s pixels are stretched into a single column vector (of shape 3072 x 1 in our example) which gets multiplied by the weights matrix and added to the bias term to get classes scores. Each row of W is independently responsible for its own class.

Another illuminating way of looking at a linear classifier is to decompose W into its rows, and reshape the resulting vectors as the image x. Looking at the slide below, this means that each 1 x 4 row of the `3 x 4`W matrix gets restructured into a 2 x 2 tiny picture. Recall, each row was responsible for a specific class. Therefore, when we reshape rows into matrices, we come up with a “template” per category, e.g. a filter which, superimposed to the input x, fires up when the overlap between the two is high enough, or when the filter matches the right patterns in x. Reverting to CIFAR10 again, take a look at the “deer-template” below. The linear model learned a central brownish blurb on a green background. Looks like deers in this dataset are always pictured in forests. Same idea for the plane in the sky. This perspective allows us to easily spot the big drawbacks of linear models as well. Take a look at the “horse-template”. The classifier extracted a central brown spot with 2 heads! Left and right-oriented. This makes sense, as CIFAR10 contains horses in both positions. This means the model, due to its lack of flexibility, is obliged to learn both at the same time. It’d be preferable to disentangle them and have the learner separate right and left-oriented horses into two different features.

The only way to achieve that is to move out of linear classifiers into more advanced approaches. Neural Networks for instance. In the following slide, we consider a 2-layer-fully-connected model, trained on CIFAR10 as well. Similarly to what we did for the linear learner, in which W could be interpreted as a set of templates each matching a class, now W_1 in the NN can be seen from the same angle. W_1 has shape 3072 x 100, e.g. it is formed of 100 32 x 32 x 32 images (templates). If we visualize those, we notice that even though most of them are not interpretable, indicating that the model is “distributing” the representation of a class across them in a non-trivial way, some are quite intriguing. Take a closer look at the two red squares. A right and a left-oriented horse, respectively! The network was able to overcome the major limitation of a linear classifier.

Why is softmax called this way? (Lesson 3)
The idea behind softmax is to turn the activations of the last layer of a neural network (unnormalized log-probabilities/logits) into probabilities, e.g. distributions of numbers summing up to 1. The final goal is generally to take the max (or better argmax) of that distribution though. So, why, don’t we take that from the logits, instead of bothering normalizing those? The index (class) corresponding to the logits’ max is going to be the same after softmax, after all. We could just return a masked vector with 1 at the position of the max and 0 everywhere else. This would be a hard-max function, and the main problem with it is that it would be non-differentiable. Or better, its gradient would be 0 almost everywhere. Not a great choice to train a NN. Soft-max, instead, is the mathematically well defined, differentiable, soft approximation of the hard-max function. Much better for a neural network.
The Adam optimizer (Lesson 4)
Whenever in doubt, use Adam. This optimizer builds on top of Momentum and RMSProp, which, on its end, is just a smarter AdaGrad. The idea is to put together the goodies of the previously formulated optimizers into a single one. The update step happens calculating an Exponential Moving Average (EMA) of the gradients (Momentum) and their square (AdaGrad/RMSProp). The learning rate is multiplied by the first and divided by the second, basically implementing a per-parameter learning rate (e.g. adaptive learning rates). The result is subtracted to the weights to update them. For Adam, beta1 = 0.9, beta2 = 0.999, and learning_rate = 1e-3, 5e-4, 1e-4 are great starting point for many models.


A 2-layer-NN in 16 lines of code (Lesson 5)

Space warping: how a matrix multiply + ReLU can separate what a line can’t (Lesson 5)
Consider the following slide. On the left side we live in the 2-dimensional x space. In x, 2 lines (the green and the red one) identify 4 regions (A, B, C, and D). We apply a linear transformation to x (multiplying it by W) and we project the green and the red lines into a new space, h, where they now represent the 2 main perpendicular axes, 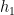
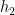

Now, let’s apply a ReLU to h, e.g. max(0, Wx), as shown in the next slide. A is positive, so it stays as it is. B lies in the region 

max(0, B) collapses all its points onto the 

max(0, D) collapses all its points onto the max(0, C) collapses all its points onto the origin. Easy.

This is an interesting behavior, as look at what happens on a toy binary-classification dataset going through the same (h=max(0, Wx))-pipeline in the following 2 slides. First we apply the linear transformation.

Then ReLU. The orange dots have been squeezed in a triangular region close to the origin, allowing them to be linearly separable from the blue ones, which have been collapsed onto the 2 h axes instead. The first linear transformation was not enough to separate the 2 classes. A nonlinearity is needed too. Interestingly, the black linear decision boundary in the h space turns into a nonlinear one if projected back into the x space.

Backprop’s pills: patterns in gradient flow (Lesson 6)
The backpropagation algorithm is used to calculate the gradients of the loss function wrt the network’s weights, which consequently fuel the SGD step. The key to understanding backprop sits in encoding the model into a computational graph. This consists in visualizing the NN as a DAG (Directed Acyclic Graph), whose nodes and edges are respectively mathematical operations (sum, multiplication, max, etc) and their relative inputs (parameters, activations, etc). The concept of DAG makes it easy to consider the two main ways of walking (passing) through it: forward and backward. The first moves from inputs to outputs, from the input x to the loss L. The second moves the other way around from outputs to inputs, from the loss L back to its gradients wrt x. Before looking at an entire graph (model) consider what happens in a single node in the following slide. x and y enter the node, where the function f crunches them to produce z (green arrows – forward pass). z gets shipped to the rest of the network until, at some point, a loss L is calculated and the backward pass (red arrows) is triggered. Gradients of L start propagating through the computational graph and, branch after branch, 
f. Continuing its downstream journey, the DAG indicates that both 

z, according to the operation occurring in f, and, invoking the chain rule in calculus, they are respectively equal to 


Now, let’s check out this in action in a simple example of a model composed of a sigmoid function only. The next slide shows the computational graph of such a network. Green numbers are outputs of the forward pass. Red numbers are backward pass gradients. The orange boxes/arrows highlight the backprop calculations in the node responsible for multiplying 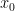




The add gate, instead, acts as a gradient distributor (see next slide). The upstream gradient is simply copied to the input edges, due to the fact the local gradients are always equal to 1 (
y). The copy node, e.g. a node responsible for naively copying its inputs to multiple output edges (like skip connections in ResNet), is the complete opposite of the add operation, acting as a gradient adder. As a perfect mirror to the add gate, its forward pass copies values (same as the backward pass for add) and its backward pass adds gradients (same as the forward pass for add). Another example is the max gate (ReLU), which behaves as a gradient router, copying the upstream gradient to the graph branch corresponding to the max input to the node, and zeroing out everything else (due to the local gradients being 

Those are very interesting behaviors, which are quite useful to keep in mind when looking at models’ architectures. Neural networks are generally built by stacking together simple blocks such as the ones we just saw, and it is important to have a sense of how gradients propagate during training.

Conv layers: # learnable params and multiply-add ops (Lesson 7)
Say your input volume is 3 x 32 x 32 and you pass it through a Conv layer with 10 5 x 5 filters (stride 1, padding 2).
- What is the output shape of the layer? That is
, e.g. same resolution as input.
- How many learnable params are there? There are 10 filters of shape
3 x 5 x 5, each contributing with a bias term, e.g.10 * 3 * 5 * 5 +10 = 760. - How many multiply-add operations are involved? The layer generates an output of shape
10 x 32 x 32, which makes a total of 10240 activations. Each one of those is computed by the element-wise product of two3 x 5 x 5regions (filter overlapping the input), e.g.10240 * 3 * 5 * 5=768000.
Receptive fields (Lesson 7)
The receptive field of an activation A of a conv layer’s output is the size of the patch of activations of the previous layer(s) that A depends on. Consider the following slide. The green square in the Output grid is depends on 9 activations (3 x 3) from the previous grid. Each one of the 3 x 3 activations in the third grid depends on 3 x 3 activations from the second grid, and so on so forth. Because of this domino effect, if you focus again on the Output and think about its network of dependencies, that single green square is relying on 3 x 3 activations from the layer Output-1, on 5 x 5 activations from two the layer Output-2 and on 7 x 7 from the layer Output-3. This is important to keep in mind as the receptive field of an activation tells us what that activation “sees” of the input image (or the previous layer).

Conv – FC layers: # params-FLOPS comparison (Lesson 8)
Something interesting to keep in mind when working with CNNs is the memory/params/FLOPS cost of the different layers constituting the network. The following slide shows an insightful trend from the AlexNet model, which translates to all CNNs. If convolutions are up to an order of magnitude more expensive in terms of floating-point operations compared to Fully-Connected (FC) layers, the inverse is true when it comes to the numbers of parameters (weights) involved in those computations. If you take a look at the chart in the center, the large majority of the entire network’s params are attributable to FC layers. This is why modern architectures try to reduce at a maximum the size of those layers, shrinking the dimensionality of features’ space via pooling (max, avg, etc) or 1 x 1 convolutions reducing the number of filters just before the final classifier.

Review of activation functions (Lesson 10)
TL;DR: just use ReLU. It works perfectly well in most cases. Never use sigmoid or tanh. See the following slide for context on relative performance. All the compared functions live in the 93-95% accuracy region on CIFAR10.

Activation functions are crucial components of a neural network, introducing nonlinearities in a combination of linear matrix multiplications. Not all activation functions are born equal though. Here a quick review of the most interesting/common ones.
Sigmoid
- Saturated neurons kill the gradients, which vanish to zero (never strictly equal to zero as ReLU) for large and small values of the inputs.
- Sigmoid outputs are not zero-centered. They are actually always positive. The main consequence is that gradients will be either always positive or always negative, which is not ideal to take appropriate gradient descent steps. This is technically true for a single item in a mini-batch and the problem gets mitigated by averaging out across it. To get an intuition of what is happening here, take a look at this thread.
- The exponential function is expensive to compute.
Tanh
- Squashes numbers to range -1, 1, meaning outputs are zero-centered (see point 2 in the above sigmoid section). Good thing.
- This function still kills the gradients due to its plateaus for high positive and negative values.
ReLU
- It does not saturate (at least in the positive region), which was a problem for both sigmoid and tanh.
- It is computationally very efficient.
- It converges much faster than sigmoid/tanh in practice (up to 6x).
- It produces non-zero-centered outputs as sigmoid, which causes the issues explained in point 2 in the above sigmoid section. This is clearly a secondary problem though, as ReLU based networks are successfully trained without much trouble.
- The gradient in the negative region is strictly zero, worse than sigmoid and tanh. In case activations are pushed to that region en-masse (might happen for entire layers’ outputs), ReLU stops propagating gradients, and weights are not updated at all anymore. This is known as the dead ReLU problem. Leaky ReLU, ELU, and SELU all address this issue adjusting the negative region of the activation function and removing the strict zero constraint.

Weight initialization (Lesson 10)
How to properly initialize weights at the beginning of training is a detail of paramount importance. The following slides clearly summarize what happens to the activations (and consequently the gradients) of a 6-layer network when drawing parameters from a Gaussian distribution with zero mean and 0.01 and 0.05 standard deviations (first and second slides respectively). This could look like a good idea but the net result is that, due also to the tanh nonlinearity, the activations are squashed to zero in the first case and to -1/1 in the second, killing the gradients. As simple and improbable as it looks, Xavier initialization (third slide) fixes this issue, dividing normal weights by the square root of the size of the input layer, and allowing activations to be nicely scaled across layers.



Choosing the hyperparameters (Lesson 11)
The following notes have been copy-pasted and re-arranged from these slides. How do we approach the problem of selecting a NN hyperparams?
- Check initial loss: turn off weight decay and sanity check loss at initialization (e.g.
log(C)for softmax with C classes). - Overfit a small sample: Try to train to 100% training accuracy on a small sample of training data (~5-10 minibatches).
- Fiddle with architecture, learning rate, weight initialization.
- Turn off regularization.
- Loss not going down? LR too low or bad initialization.
- Loss explodes to Inf or NaN? LR too high or bad initialization.
- Find LR that makes loss go down
- Use the architecture from the previous step.
- Use all training data.
- Turn on small weight decay.
- Find a learning rate that makes the loss drop significantly within ~100 iterations.
- Good learning rates to try: 1e-1, 1e-2, 1e-3, 1e-4.
- Coarse grid, train for ~1-5 epochs: Choose a few values of learning rate and weight decay around what worked from Step 3, train a few models for ~1-5 epochs. Good weight decay to try: 1e-4, 1e-5, 0.
- Refine grid, train longer: Pick best models from Step 4, train them for longer (~10-20 epochs) without learning rate decay.
- Look at loss curves
- GOTO step 5
RNN: Vanilla and LSTM (Lesson 12)
The simplest implementation of a Recurrent Neural Network (Vanilla) is based on a functional form that, at time step t, takes the input 
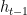



It is important to realize that the weights matrices 


Does backpropagation work through so many steps? Not really. The first problem is that it requires a lot of GPU memory to store the entire computational graph (back and forth). A solution here is to avoid going back all the way to the beginning of the sequence and processing a smaller chunk of fixed length instead. This is known as Truncated Backpropagation Through Time, shown below.

The second problem becomes apparent when calculating the gradients. The recurrent nature of a Vanilla RNN means that the same weights matrices are multiplied by each other over and over. This behavior in the forward pass is equivalent to what happens in the backward one, meaning that “small” and “big” matrices will “reinforce” themselves, leading to vanishing and exploding gradients respectively.

If exploding gradients could be addressed by gradient clipping, nothing obvious can be invoked for the vanishing ones. LSTM to the rescue. LSTMs keep the recurrent nature of their Vanilla version, upgrading the recurrent cell instead. The below slide visualizes the operations occurring inside one of those cells. Note that, at time step t, an LSTM is fed 3 inputs (one more of the Vanilla RNN): 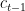

How does such a structure help? The reason is that backpropagating from 
f, with no direct involvement of W (see below). This creates a natural “highway” over which the gradients can flow in an almost undisturbed way. Even if gradients explode/vanish in the rest of the network, the cell-state-highway guarantees information will keep propagating, adding a trick very similar to the skip connection in the ResNet architecture.

Attention (Lesson 13)
Attention mechanisms have revolutionized the field of NLP since their groundbreaking results with the introduction of the Transformer architecture back in 2017 (on top of the lecture, here another great resource). The main idea behind Attention is that each output in the sequence depends on ALL the inputs at the same time, where each input gets weighed according to how much the network needs it to produce the output. This result is obtained by:
- applying linear transformations to the inputs X and turning those into Query (Q), Key (K), and Value (V) vectors. Beware that Query vectors are a result of a linear transform of X only for a Self-Attention layer. Otherwise, they are vectors calculated independently outside of the Attention layer. What is the intuition behind Q, K, and V?
- A Query gives the model the opportunity to ask “this is what I am interested in. Give me a relevant response to this query”. That’s what you type on the Google search bar (me asking Google: “How tall is the Empire State building?”).
- A Key represents an indexed database storing the current information of the sequence. That’s what Google matches your query against (Google searching for documents containing the Empire State building info).
- A Value is the result of the match between Q and K. That’s what Google returns as relevant search results (Google replying: “It’s N feet tall”).
- Q, K, and V are all (at least for Self-Attention) related to the inputs X. In different ways though, which is why they undergo linear transformations first, e.g. getting multiplied by learnable weights matrices.
- multiplying them together to assess their similarity in the new features spaces they have been projected onto
- normalizing those similarity scores
- taking linear combinations of the transformed inputs weighted by the normalized scores.
The visualizations below (from the slides of the course) are one the best I have found online to describe what is actually happening in an Attention and (most importantly) a Self-Attention Layer. The third slide shows a Multihead + Masked Self-Attention mechanism, two of the building blocks of the Transformer architecture (last viz).







Comments are closed.