
Note: Javier in this post shared another (very cool way) of addressing extreme class imbalance: Focal Loss. Directly borrowed from Object Detection, it is available in LightGBM and XGBoost. Check here and here.
If you found yourself in this scenario and you had absolutely no clue of what to do, welcome to the club.
I don’t have a lot of experience dealing with imbalanced datasets, after all. The worst beast I faced in the past had been a binary classification with a 90-10% class split. Technically, this already qualifies as imbalanced. If not handled properly, it can degenerate into pretty nasty disasters. It is still doable, though. In my case just optimizing ROC AUC, instead of accuracy, and using balanced Random Forest, instead of the standard algo, did the trick. I obtained very good results and almost no sweat.
I recently stumbled upon a 99.9-0.1% class split, and this is a completely different story.
The purpose of this post is to illustrate the experiments I have performed along the journey within the highly imbalanced world. Here a list of all the algorithms/strategies I tested:
- Balanced Random Forest
- Data set resampling
- Ensembling + Oversampling (this worked best for me)
- XGBoost
- SVM, KNN, more classical anomaly detection techniques
Let’s get started.
First things first: performance metrics
This is a real nightmare when dealing with such a highly imbalanced data set. Accuracy is not an option, obviously. Any off-the-shelf classifier would score 99.9% if rated against accuracy. Completely useless.
We need richer performance indicators. I wrote my own handy function to easily check how I was doing. `print_report` is in charge of calculating and returning
- ROC AUC and F1 scores for both training and validation set
- Precision and Recall on the validation set
- Confusion Matrix on the validation set. This is by far the most useful of all the metrics combined. The tabular form of a Confusion Matrix is the easiest way to immediately check what the model is doing. In a glance, you get an overview of where the problem is. If you have to choose, drop all the rest and focus on this one only. Cannot recommend it enough.
`print_report` accepts both single classifiers and ensembles, as long as they support the predict_proba method. This is critical as, especially when dealing with highly imbalanced data sets, tuning the classification probability threshold is a must. The 50% default is almost always not optimal and, according to specific business requirements, we might want to either decrease or increase it, to accordingly prioritize precision or recall. Therefore, `print_report` accepts as input a number between 0 and 1 (defaults to 0.5) which is used to decide how to assign each observation to each label. Bellow the full code, with relative dependencies.
def plot_confusion_matrix(cm, classes,
title='Confusion matrix validation set',
cmap=plt.cm.Blues):
"""
plot_confusion_matrix prints and plots the cm
confusion matrix received in input.
"""
plt.imshow(cm, interpolation='nearest', cmap=cmap)
plt.title(title)
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes)
plt.yticks(tick_marks, classes)
fmt = 'd'
thresh = cm.max() / 2.
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, format(cm[i, j], fmt),
horizontalalignment="center",
color="white" if cm[i, j] > thresh else "black")
plt.ylabel('True label')
plt.xlabel('Predicted label')
plt.tight_layout()
def predict_ensemble(ensemble, X):
"""
predict_ensemble runs the X data set through
each classifier in the ensemble list to get predicted
probabilities.
Those are then averaged out across all classifiers.
"""
probs = [r.predict_proba(X)[:,1] for r in ensemble]
return np.vstack(probs).mean(axis=0)
def adjusted_classes(y_scores, t):
"""
This function adjusts class predictions based on the prediction threshold (t).
Will only work for binary classification problems.
"""
return [1 if y >= t else 0 for y in y_scores]
def print_report(m, X_valid, y_valid, t=0.5, X_train=None, y_train=None):
"""
print_report prints a comprehensive classification report
on both validation and training set (if provided).
The metrics returned are AUC, F1, Precision, Recall and
Confusion Matrix.
It accepts both single classifiers and ensembles.
Results are dependent on the probability threshold t
applied to individual predictions.
"""
X_train = X_train.values
X_valid = X_valid.values
if isinstance(m, list):
probs_valid = predict_ensemble(m, X_valid)
y_val_pred = adjusted_classes(probs_valid, t)
if X_train is not None:
probs_train = predict_ensemble(m, X_train)
y_train_pred = adjusted_classes(probs_train, t)
else:
probs_valid = m.predict_proba(X_valid)[:,1]
y_val_pred = adjusted_classes(probs_valid, t)
if X_train is not None:
probs_train = m.predict_proba(X_train)[:,1]
y_train_pred = adjusted_classes(probs_train, t)
res = [roc_auc_score(y_valid, probs_valid),
f1_score(y_valid, y_val_pred),
confusion_matrix(y_valid, y_val_pred)]
result = f'AUC valid: {res[0]} \nF1 valid: {res[1]}'
if X_train is not None:
res += [roc_auc_score(y_train, probs_train),
f1_score(y_train, y_train_pred)]
result += f'\nAUC train: {res[3]} \nF1 train: {res[4]}'
print(result)
plot_confusion_matrix(res[2], classes=['Positive', 'Negative'])
print(classification_report(y_valid, y_val_pred))Now we can start deep diving into the methods.
Balanced Random Forest
My first attempt consisted in running the entire data set through a Penalised Random Forest, i.e. a version of the algorithm which balances each class by the inverse of its frequency. Even after hyper-parameter and probability threshold tuning, results were very poor (any model would pretty much always predict the positive class).
RF has almost never disappointed me. Even with rather complicated datasets, the magic of `class_weight=’balanced’` worked pretty well. Not this time. A 99.9-0.1% split is too extreme. Therefore, I immediately turned my attention at ways to address the imbalance at the data set level. Sampling techniques topped the list of promising candidates.
Resampling
Sampling, either up/over or down/under, is a very known (and recommended) strategy when it comes to tackling class imbalance. The former consists in increasing the size of the minority class to match the majority class. The latter consists in reducing the size of the majority class to match the minority class. In terms of how to do that in practice, the imbalanced-learn python library comes to the rescue. `imblearn` offers a lot of sampling options, among other incredibly useful features. Super recommended.
Undersampling strategies
An obvious way of undersampling the majority class is to randomly sample a small subset of its data points (RandomUnderSampler). Small enough to roughly match the size of the minority class. This basically means throwing away a lot of information but also, in the end, having a balanced data set.
A more sophisticated approach is based on computing Tomek’s links between two samples of different classes (`TomekLinks`). Here the idea is to find points which are nearest neighbors and belonging to opposite classes. Whenever the two conditions are met a Tomek link is found and the majority class data point can be removed. The below image shows a Tomek link between two observations.

Oversampling strategies
In case we wanted to increase the size of the minority class, the situation is a little subtler as, technically, we’d need to create new data points. The easy solution involves just copying the minority class over and over, i.e. sampling with repetition until the desired amount of observations is reached (`RandomOverSampler`).
Another option is to actually create new observations from scratch. There are several ways of addressing this need (SMOTE/ADASYN). All of those are slight deviations from a common baseline strategy, consisting in randomly perturbing the existing data points to generate new ones. From the imbalanced-learn documentation:
Considering a sample
imbalanced-learn docs, a new sample
will be generated considering its
kneareast-neighbors […]. For instance, the 3 nearest-neighbors are included in the blue circle as illustrated in the figure below. Then, one of these nearest-neighborsis selected and a sample is generated as follows:
whereis a random number in the range
[0, 1]. This interpolation will create a sample on the line betweenand
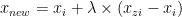

In my case, the biggest problem was that I only had ~100 negative samples over a total of ~125k. In such a scenario, undersampling the majority class did not look like an option to me. I would have lost too much valuable data and would have ended up with a dataset in the hundreds anyway. Oversampling seemed way better. I tried a number of oversampling techniques, in the attempt to rebalance the entire dataset, and then I run a Random Forest on top of the result. The outcomes were encouraging. Far from being satisfactory, but still encouraging. In my previous experiment with a Penalised RF, no matter how I tweaked hyperparameters and probability threshold, the model would always predict the positive class. I had zero predictive power. Oversampling the data set first, instead, helped the algorithm to build a more reliable class boundary.
Nevertheless, I was still facing a very basic issue. Completely rebalancing the data set meant filling a 1250:1 ratio between the two classes. This is too big of a gap to be addressed in one single step. This observation sparked the idea I explore in the next section.
In the meantime, take a look at how easy it is with to achieve what we just discussed with `imblearn`:
from imblearn.over_sampling import RandomOverSampler, SMOTE, ADASYN
RANDOM_STATE=42
# just uncomment the oversampling strategy you want to experiment with
ros = RandomOverSampler(random_state=RANDOM_STATE)
#ros = SMOTE(random_state=RANDOM_STATE)
#ros = ADASYN(random_state=RANDOM_STATE)
X_resampled, y_resampled = ros.fit_resample(X_train, y_train)
# this is just to check if now the 2 classes are equally distributed
print(sorted(Counter(y_resampled).items()))
rf = RandomForestClassifier(n_jobs=-1, random_state=RANDOM_STATE,
n_estimators=100, min_samples_leaf=11)
rf.fit(X_resampled, y_resampled);
print_report(rf, X_valid, y_valid, t=0.4, X_train=X_train, y_train=y_train)Ensembling + Oversampling
As I said, replicating the negative observations ~1250 times to match the size of the positive ones was probably not a good idea. Too big of a step to be filled in one go. Oversampling went in the right direction, though, and I didn’t want to lose this edge. Maybe a better option could be to divide the majority class in parts and append to each of these the negative points. Doing that I would create smaller data sets affected by a way less extreme imbalance.
The approach consisted of an ensemble of Random Forest classifiers trained on a number of data sets artificially re-balanced via up/down-sampling techniques. In a nutshell:
- Select and randomly shuffle the observations from the majority class.
- Split #1 into N chunks.
- Append to each one of those chunks the data points from the minority class. This basically means creating N brand new training sets.
- Re-balance the new data sets via a sampling technique selected randomly among a number of possible under-sampling, over-sampling and hybrid strategies.
- Fit a separate RF classifier on each re-balanced data set.
- Predict on the validation set by ensembling the predictions of the independent models.
This is, by far, the approach which worked the best, reaching more than decent precision and recall.
Below, for clarity, a visualisation of the strategy.

Here, instead, the `train_ensemble` function taking care of the implementation. It supports instances of sklearn.ensemble.RandomForestClassifier and xgb.XGBClassifier. For the latter, it expects an already fine-tuned estimator from which to extract the relevant hyperparameters (refer to the XGBoost section for more details).
def train_ensemble(est_name, n_split, oversample=True):
"""
train_ensemble splits the train set corresponding to the
majority class (0 in this case) in n_split random chunks.
It then builds n_split new train sets concatenating each chunk
with train set corresponding to the minority class (1 in this case).
It then applies a random sampling strategy, among 7 possible,
to each of the n_split new train sets and trains an est_name
classifier on top of it.
It reurns a list of n_split classifiers.
"""
pos = y_train[y_train.values == 0].index.values
neg = y_train[y_train.values == 1].index.values
np.random.shuffle(pos)
pos_splits = np.array_split(pos, n_split)
ensemble = []
for i, chunk in enumerate(pos_splits):
idx = np.hstack((neg, chunk))
X_t, y_t = X_train.loc[idx], y_train.loc[idx]
if oversample:
ros = random.choice([SMOTE(), ADASYN(), RandomOverSampler(),
SMOTEENN(), SMOTETomek(), RandomUnderSampler(), TomekLinks()])
X_resampled, y_resampled = ros.fit_resample(X_t, y_t)
if i % 20 == 0: print(sorted(Counter(y_t).items()), sorted(Counter(y_resampled).items()))
else:
X_resampled, y_resampled = X_t, y_t
if est_name == 'rf':
est = RandomForestClassifier(n_jobs=-1, class_weight='balanced',
n_estimators=100, min_samples_leaf=9)
elif isinstance(est_name, xgb.sklearn.XGBClassifier):
est = xgb.XGBClassifier(objective = 'binary:logistic', scale_pos_weight=1200)
est.set_params(n_estimators= est_name.get_params()['n_estimators'],
learning_rate= est_name.get_params()['learning_rate'],
subsample= est_name.get_params()['subsample'],
max_depth= est_name.get_params()['max_depth'],
colsample_bytree= est_name.get_params()['colsample_bytree'],
min_child_weight= est_name.get_params()['min_child_weight']);
est.fit(X_resampled, y_resampled)
ensemble.append(est)
return ensemble
ensemble_rf = train_ensemble('rf', 100)
# output
[(0, 871), (1, 77)] [(0, 832), (1, 77)]
[(0, 871), (1, 77)] [(0, 837), (1, 77)]
[(0, 871), (1, 77)] [(0, 871), (1, 854)]
[(0, 871), (1, 77)] [(0, 871), (1, 858)]
[(0, 870), (1, 77)] [(0, 870), (1, 870)]XGBoost
Last but not least I have experimented with XGBoost as well.
XGBoost (eXtreme Gradient Boosting) is an advanced implementation of gradient boosting algorithm (same family as GBM). It is a well known approach within the family of trees ensembles, and a common choice for its speed and accuracy. The big drawback is that it almost never works off the shelf but it requires careful tuning. It also supports dealing with imbalanced dataset. It scales the importance of the majority class by the scale_pos_weight parameter passed as input to the classifier.
The process I have followed is the following:
- I tuned XGBoost’s hyperparameters via a standard 5-fold CV on the entire training set. Take a look here for a super detailed post around how to properly fine-tune this algorithm.
- I tested the resulting best estimator on its own. Performance was really poor here, even after playing around with the probability threshold.
- I applied the same sampling + ensembling strategy explained in the previous paragraph, fitting N independent classifiers initialized with the best estimator’s hyper-parameters. Results, again, were worse than the ones obtained with the same approach using RF.
clf_xgb = xgb.XGBClassifier(objective = 'binary:logistic', scale_pos_weight=1200)
param_dist = {'n_estimators': stats.randint(150, 500),
'learning_rate': stats.uniform(0.01, 0.07),
'subsample': stats.uniform(0.3, 0.7),
'max_depth': [3, 4, 5, 6, 7, 8, 9],
'colsample_bytree': stats.uniform(0.5, 0.45),
'min_child_weight': [1, 2, 3]
}
sfk = StratifiedKFold(shuffle=True, n_splits=5)
clf = RandomizedSearchCV(clf_xgb, param_distributions = param_dist, n_iter = 10,
scoring = 'f1', error_score = 0, verbose = 3, n_jobs = -1, cv=sfk)
clf.fit(X_train.values, y_train);
# checking performance of best estimator
print_report(clf.best_estimator_, X_valid, y_valid, t=0.4, X_train=X_train, y_train=y_train)
# training an xgb ensemble, given the fine tuned best estimator
ensemble_xgb = train_ensemble(clf.best_estimator_, 100)
# checking performance of the ensemble
print_report(ensemble_xgb, X_valid, y_valid, t=0.4, X_train=X_train, y_train=y_train)Other approaches
I have also tried a couple of non-tree-ensembles strategies. Here my comments:
- SVM, both with a Linear and a Gaussian kernel. Results were very poor, though. On top of that, training times were incredibly bad (10x slower than RF), which obliged me to quickly drop the algorithm as any fine-tuning would have been too time-consuming.
- KNN: here, again, results were really poor. Even after tuning
n_neighborsand the probability threshold, I never managed to get outcomes nearly as good as the ones Trees Ensembles provided. - More classic anomaly detection (AD) techniques. I briefly looked into this domain too (KNN is actually commonly used in AD). I have to admit that I am not very familiar with this branch of statistical learning and my low level of expertise did not allow me to get very far. I still wanted to give it a stab. Anomaly detection approaches mainly consist in fitting a specific distribution (Gaussian is a common choice) to the underlying data. Any observation deviating significantly from the learned curve is flagged as anomaly (or outlier). I tried to check whether it was possible to implement a simple time-series based AD, i.e. processing
attributes once at a time and looking at potential spikes. This is, in a nutshell, the strategy used in low-pass (or Kalman) filters. Again, I was not able to obtain any decent result and I quickly opted out.
Final thoughts on performance
At the end of the day, any classification task involving such an extreme imbalance cannot be addressed properly without deep domain knowledge. This kind of know-how is mostly relevant when it comes to decide what to prioritise between precision and recall. Is the cost of a FP higher or lower than the cost of a FN? It all boils down to that. Obviously, as data scientists, we strive to minimise both. The truth is that, in most cases, a choice has to be made, as optimal performance on both can hardly be achieved.



Comments are closed.