
Links to code: Jupyter notebook with model training. Lambda function. JS and HTML for frontend page. Dockerfile to deploy on Lambda.
The context
In this post, we will train an object detector in IceVision to recognize LaTeX symbols in handwritten math, and deploy the solution on AWS Lambda via its newly added Docker support. I will spend just a few words on the training part, focusing mainly on the deployment section, with the intent of sharing my learning experience as accurately as possible.
The inspiration behind this post came from the very recent announcement (1 Dec 2020) around Container Image support for AWS Lambda. I immediately found the news a potential game-changer in terms of making serverless technology more flexible and accessible. As a serverless user myself, especially in the ML domain, I have always thought Lambda was quite hard to customize. Lambda Layers are the official way of adding libraries not supported by the available runtimes, but this is still convoluted, and Docker sounded like the perfect approach to address all the missed points in terms of flexibility.
The deployed web application
First things first. Let’s take a quick glance at how the end result looks like. Here you can find a short video in which I interact with the application on VisualNeurons. I process two images: one from the dataset, and a math expression I scribbled myself on a piece of paper, taking a picture of it with my phone. The results are quite impressive! Take a shot at it yourself, keeping in mind that the model was trained on 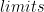

The data and the model: IceVision takes the stage
The data I used consists of a 10k random sample (to speed up prototyping) from the Aida Calculus Math Handwriting Recognition Dataset on Kaggle. Originally composed of 100k images split in 10 batches, this dataset contains photos of a handwritten calculus math expression (specifically within the topic of limits) written with a dark utensil on plain paper. Each image is accompanied by ground truth math expression in LaTeX as well as bounding boxes and pixel-level masks per character. All images are synthetically generated. A selection of three of them is displayed next.



As for the model, I opted for Faster R-CNN. As you can see from the notebook, I achieved ~86.3% mAP in 11 epochs. Each epoch took roughly 20 minutes, training on 8k images and validating on 2k (randomly split), on an ml.p3.2xlarge SageMaker Notebook instance (1 Tesla V-100 GPU). I tried Retinanet and EfficientDet as well, but they were both slower and less performant, so I stuck to Faster R-CNN. As for the training itself, I used the rock-solid lr_find + fine_tune fastai approach.
Fast experimentation (a key factor for success in most ML projects) was entirely made possible by adopting the IceVision (IV) library. For the ones who are not familiar with it, IV streamlines computer vision tasks, providing a concise and effective API allowing users to parse data and train models in a few lines of code. Getting such pipelines right is notoriously difficult, as they generally require a lot of custom boilerplate code, which is not flexible and very error-prone. If you take a look at my notebook, you’ll notice how IceVision addresses all those pain points in a super clean way. The library started as an Object Detection framework mainly, but it is expanding rapidly to cover a lot more than that. Check it out, we are a very vibrant and welcoming community on Discord.
Architecting on AWS
The web app architecture is quite standard for an ML-based deployment, identical to the Fast Neural Style Transfer one, described here. Its simplicity and elegance clearly speak in favour of the flexibility and robustness of a serverless solution. Another huge benefit to keep in mind is that, for low traffic applications, Lambda is significantly cheaper than any other deployment option. The smallest SageMaker machine costs ~50 USD/month, given it is up and running 24/7. The underlying pillar of serverless is that, well it is server-less, so you pay for each function invocation, making it ideal for a toy project. The workflow unrolls as follows:
- The website (VisualNeurons), is hosted as a static site on a public S3 bucket, with Amazon Route 53 redirecting internet traffic to it automatically.
- The user uploads a picture with the handwritten math expression he wishes to submit to the model.
- By hitting
Extract LaTeX!a POST request is sent to a REST API, deployed via Amazon API Gateway, with the base64-encoded image as payload. - The API triggers an AWS Lambda call, which basically consists of invoking its `handler` function. This is where the magic happens.
- The Faster R-CNN model is defined and loaded from disk.
- The image is decoded from base64 (here)
- converted to PIL (here)
- and transformed (turned into a Torch Tensor, resized and normalized). This is specifically achieved by loading the image into a Dataset.
- A Dataloader is created on top of the Dataset and a batch (of size 1) is passed through the model for inference (here).
- Bounding Box predictions and related labels are drawn on top of the original image.
- Padding (added during step 4) is removed
- and the resulting PIL image is base64-encoded and wrapped into a JSON to be sent back as a POST response (here).
- Lambda returns a JSON to the frontend. JavaScript reads it and displays the image on a canvas.
The big novelty here occurs at step 4, which is entirely wrapped inside a Docker image. We’ll dive into it in the next section.
Get Docker to work on AWS Lambda
This post does a terrific job at walking you through the setup of a Lambda-compatible Docker image. I mostly followed it, with a mix and match of a couple of additional AWS resources, and direct help from Danilo Poccia himself, when I hit a big roadblock on my way. Let’s review in detail what I did.
Write your Dockerfile
This is the obvious first step: put together a Dockerfile to build your image. Do it locally, of course. You want to be able to quickly iterate, test, and debug whatever might be going wrong before moving to the cloud.
Given the flexibility of Docker, in principle, you can do pretty much anything you want here. According to the documentation, Lambda supports all Linux distributions, such as Alpine, Debian, and Ubuntu, so you could pick a base image from any of those OS. In practice, as previously stated, you want to test your Lambda function locally, and to do that you need the Lambda Runtime Interface Client (RIC) dependency, a library that makes it possible to emulate a Lambda call on your laptop. You have 3 options here:
- Use AWS-maintained base images that come pre-packaged with all the needful. From the Docker Hub page: “AWS provided base images for Lambda contain all the required components to run your functions packaged as container images on AWS Lambda. These base images contain the Amazon Linux Base operating system, the runtime for a given language, dependencies and the Lambda Runtime Interface Client (RIC), which implements the Lambda Runtime API. The Lambda Runtime Interface Client allows your runtime to receive requests from and send requests to the Lambda service.”
- Add RIC to the image. Look here for the section Building a Custom Image for Python.
- Install RIC onto your local machine, without adding it to the image. Look here for the section Not Including the Lambda Runtime Interface Emulator in the Container Image.
I tested all of them and the only one which ended up working was the first, AWS-maintained base images. I stumbled on all sorts of issues with the remaining two, mostly fuelled by very confusing documentation and cryptic error messages. Long story short, here is my Dockerfile (named Dockerfile.icevision for future reference):
# Dockerfile.icevision.
FROM public.ecr.aws/lambda/python:3.8
RUN yum -y update
RUN yum -y install gcc
RUN yum install -y git
COPY requirements.txt ./requirements.txt
RUN pip install -r requirements.txt \
&& pip install -e git://github.com/FraPochetti/mantisshrimp.git@aws-lambda#egg=icevision[inference] --upgrade -q
COPY model_dir ./model_dir
COPY /app/app.py ./
CMD ["app.handler"] Let’s check this out line by line.
FROM public.ecr.aws/lambda/python:3.8We use the Lamba-compatible python Docker images maintained by AWS as a base.
RUN yum -y update
RUN yum -y install gcc
RUN yum install -y gitInstall gcc and git, needed later on.
COPY requirements.txt ./requirements.txt
RUN pip install -r requirements.txt \
&& pip install -e git://github.com/FraPochetti/mantisshrimp.git@aws-lambda#egg=icevision[inference] --upgrade -qCopy `requirements.txt` (below) and install dependencies from there. Then install icevision[inference]. I will elaborate on why I was obliged to install from a personal branch of mine, instead of using the official PyPi package (yes, you guessed right, a Lambda related issue).
# requirements.txt
--find-links https://download.pytorch.org/whl/torch_stable.html
torch==1.7.1+cpu
torchvision==0.8.2+cpuCopy the contents of the model_dir folder, containing:
labels.pkl: pickled list of human-readable labels. Needed to convert prediction labels.model_final.pth: weights of the Faster R-CNN trained model.- `test1.jpg`: an image needed to test Lambda before invoking the function with actual POST requests from the REST API.
COPY model_dir ./model_dirCopy the `app.py` file, containing the actual Lambda function implementation, and linking Lambda invocation to the `handler` function (e.g. handler is what gets called when invoking Lambda). So, yes, in case you are wondering, the function is wrapped inside the Docker image and, once in the AWS console, you won’t have access to it in the familiar Cloud9 embedded IDE. Any edits to it involve rebuilding the Docker image from scratch. Keep it in mind.
COPY /app/app.py ./
CMD ["app.handler"]This is the `app.py` file I used in the early stages of the project, just to test if I could successfully run a container on top of the image and call Lambda. It is super basic but it is useful to keep it that way at the beginning.
# app.py used in the early stages of the project just to test if I was able to import the icevision library
import sys
import icevision
def handler(event, context):
return 'Hello from AWS Lambda using Python ' + sys.version + ' and IceVision ' + icevision.__version__ + '!'Build the image and run Lambda locally
Navigate to the folder where the `Dockerfile.icevision` file is located and run
docker build -t icevision -f Dockerfile.icevision .If everything goes as expected, executing “`docker images`” should return the following.

Now open a terminal and enter the following command to spin up a container on top of the image we just built. Once up and running, the application will be listening to port 9000 in localhost.
docker run -p 9000:8080 --rm icevisionIn a second terminal window type this line. `curl` will send a POST request to Lambda with an empty payload (“{}”).
curl -XPOST "http://localhost:9000/2015-03-31/functions/function/invocations" -d '{}'Recall that our `handler` does nothing else than importing libraries and returning a string with packages’ versions, hence the result of the previous command should be
"Hello from AWS Lambda using Python 3.8.5 and IceVision 0.5.2!"If this is what you got, congratulations! You have a fully functioning Lambda-compatible Docker image.
Wait, do you? Not really. Time to address the reason why I am installing IceVision from a personal branch of mine instead of the official PyPi repo.
What is silently going wrong locally
At this point, you’d normally feel very confident that you got everything right and that you can safely move to the cloud. Let me fast-forward a bit, skip the move-to-the-cloud part (which we will address in the next section), and pretend we are already invoking Lambda from within the AWS console. To my surprise, when I did that, I got error messages as the ones showed below. I am pasting CloudWatch stack traces at different time steps during my debugging process, e.g. when I was actively changing things here and there to figure the problem out (rebuilding the image each time and re-uploading to AWS), which is why the error message changes.
[ERROR] FileNotFoundError: [Errno 2] No such file or directory: '/home/sbx_user1051/.icevision'
Traceback (most recent call last):
File "/var/lang/lib/python3.8/imp.py", line 234, in load_module
return load_source(name, filename, file)
File "/var/lang/lib/python3.8/imp.py", line 171, in load_source
module = _load(spec)
File "<frozen importlib._bootstrap="">", line 702, in _load
File "<frozen importlib._bootstrap="">", line 671, in _load_unlocked
File "<frozen importlib._bootstrap_external="">", line 783, in exec_module
File "<frozen importlib._bootstrap="">", line 219, in _call_with_frames_removed
File "/var/task/app.py", line 2, in <module>
import icevision
File "/var/lang/lib/python3.8/site-packages/icevision/__init__.py", line 1, in <module>
from icevision.utils import *
File "/var/lang/lib/python3.8/site-packages/icevision/utils/__init__.py", line 6, in <module>
from icevision.utils.data_dir import *
File "/var/lang/lib/python3.8/site-packages/icevision/utils/data_dir.py", line 6, in <module>
root_dir.mkdir(exist_ok=True)
File "/var/lang/lib/python3.8/pathlib.py", line 1287, in mkdir
self._accessor.mkdir(self, mode)</module></module></module></module></frozen></frozen></frozen></frozen>[ERROR] OSError: [Errno 30] Read-only file system: '/home/sbx_user1051'
Traceback (most recent call last):
File "/var/lang/lib/python3.8/imp.py", line 234, in load_module
return load_source(name, filename, file)
File "/var/lang/lib/python3.8/imp.py", line 171, in load_source
module = _load(spec)
File "<frozen importlib._bootstrap="">", line 702, in _load
File "<frozen importlib._bootstrap="">", line 671, in _load_unlocked
File "<frozen importlib._bootstrap_external="">", line 783, in exec_module
File "<frozen importlib._bootstrap="">", line 219, in _call_with_frames_removed
File "/var/task/app.py", line 2, in <module>
import icevision
File "/var/task/src/icevision/icevision/__init__.py", line 1, in <module>
from icevision.utils import *
File "/var/task/src/icevision/icevision/utils/__init__.py", line 6, in <module>
from icevision.utils.data_dir import *
File "/var/task/src/icevision/icevision/utils/data_dir.py", line 6, in <module>
root_dir.mkdir(exist_ok=True, parents=True)
File "/var/lang/lib/python3.8/pathlib.py", line 1291, in mkdir
self.parent.mkdir(parents=True, exist_ok=True)
File "/var/lang/lib/python3.8/pathlib.py", line 1287, in mkdir
self._accessor.mkdir(self, mode)</module></module></module></module></frozen></frozen></frozen></frozen>If you take a moment and read what Python is complaining about, you’ll spot that directories needed by IceVision at import time are not already present (which is fine) and cannot be created due to permissions issues. `data_dir.py` is the root cause of the problem.
# ORIGINAL data_dir.py
__all__ = ["get_data_dir", "get_root_dir"]
from icevision.imports import *
root_dir = Path.home() / ".icevision"
root_dir.mkdir(exist_ok=True)
data_dir = root_dir / "data"
data_dir.mkdir(exist_ok=True)
def get_data_dir():
return data_dir
def get_root_dir():
return root_dirWhy cannot IceVision run `data_dir.mkdir(exist_ok=True)`? Because of the Lambda requirements for container images, among which, the second and the third read:
- The container image must be able to run on a read-only file system. Your function code can access a writable
/tmpdirectory with 512 MB of storage. If you are using an image that requires a writable directory outside of/tmp, configure it to write to a directory under the/tmpdirectory. - The default Lambda user must be able to read all the files required to run your function code. Lambda follows security best practices by defining a default Linux user with least-privileged permissions. Verify that your application code does not rely on files that other Linux users are restricted from running.
This is a big problem (Danilo pointed me in this direction actually) as it means we cannot create directories where we want. There is no simple way out of this, of course. IceVision imports fail, period. Therefore, the only thing I figured I could do is to edit the source code and remove those `mkdir` statements (checking if this change does not break anything at inference time!). Here how `data_dir.py` looks like after my edits. Easy-peasy.
# data_dir.py AFTER REMOVING THE mkdir COMMANDS
__all__ = ["get_data_dir", "get_root_dir"]
from icevision.imports import *
root_dir = Path(".")
data_dir = root_dir / "data"
def get_data_dir():
return data_dir
def get_root_dir():
return root_dirI then pushed the changed file to a new branch of a forked `icevision` repo to be able to install from there. Once done, I rebuilt the Docker image, pushed it to AWS and I could successfully invoke Lambda.
This whole issue took me by surprise and a question kept bugging me all along the way: given the whole purpose of Docker is to avoid those platform-related inconsistencies, how come no errors were thrown locally whereas problems arose only on AWS? I have to admit I was not able to get a good answer to that, and I find it rather annoying as it might undermine the benefits of using Docker in the first place.
Push the image to Amazon ECR
Note: the Lambda function, e.g. the app.py file, I ended up packaging into the image is this one, not the dummy `handler` we used for testing!
We are now ready to push the image to ECR. We first create an ECR repository, then tag the image we built locally following the AWS convention, login into ECR and finally push.
aws ecr create-repository --repository-name lambda-images --image-scanning-configuration scanOnPush=true
docker tag icevision:latest <aws account="" id="">.dkr.ecr.eu-west-1.amazonaws.com/lambda-images:icevision
aws ecr get-login-password | docker login --username AWS --password-stdin <aws account="" id="">.dkr.ecr.eu-west-1.amazonaws.com
docker push <aws account="" id="">.dkr.ecr.eu-west-1.amazonaws.com/lambda-images:icevision</aws></aws></aws>After tagging, “`docker images`” should return the following:

Here is instead how my ECR console looks like after pushing the image. Quite a few of them up there!

Create a Lambda function on top of the `icevision` Docker image
After all we have gone through, this is the easiest part, by far. Creating a Lambda function on top of a Docker image amounts to just selecting the image URI. That’s it.

Upon hitting Create, you will land on the Lambda function page (below). As mentioned earlier, given all the relevant code is wrapped into the image, you don’t get the nice Cloud9 IDE functionality inside the console. Each time you need to edit the function, you are obliged to rebuild the image locally, push it and redeploy the new one to Lambda.

What we have left to do is simply create the REST API with API Gateway (covered here in detail), add it as a trigger to Lambda, and take care of the frontend on VisualNeurons. I won’t deep dive into those as I have covered this part in other posts of mine.
SageMaker: customizing your Python environment
This is an extra section I am devoting to how to build a custom python environment in SageMaker. The notebook I used to train the latex detector has been executed as a SageMaker Notebook, and it required some jiggling to get set things up. It is very important to know how to effectively manage environments to streamline libraries’ installations, so let’s check it out.
Automating libraries’ installation in SageMaker Notebooks
IceVision doesn’t come with any of the pre-installed anaconda environments within SageMaker Notebooks. We can get it manually each time the instance is started, but this is far from being ideal. It’d be way better to have the task automated: meet Lifecycle Configurations (LC). LCs are scripts that can be executed either at notebook creation time, e.g. just once, or each time an instance is started.

Here the lifecycle configuration I set up for my notebook each time it was fired up. Instructions are very simple: the `python3` environment is activated and IceVision is installed together with another couple of useful libraries. Very practical.
#!/bin/bash
set -e
sudo -u ec2-user -i >>'EOF'
ENVIRONMENT=python3
source /home/ec2-user/anaconda3/bin/activate "$ENVIRONMENT"
pip install icevision[all] icedata
pip install ipywidgets
jupyter nbextension enable --py widgetsnbextension
source /home/ec2-user/anaconda3/bin/deactivate
EOFSageMaker Studio: add a custom conda environment with Docker
This is even more interesting. SageMaker Studio brings the game to the next level allowing users to set Docker images as environments. We love Docker as it guarantees full flexibility and customizability, so let’s dive a little deeper here.
For the sake of transparency, I didn’t eventually use Studio because, for unknown reasons, I was not able to get the ml.p3.2xlarge to work with my Docker image. Or the other way around. I was not able to understand which of the two sides the incompatibility came from. My environment worked perfectly with any other machine I tested, though, but I really needed the speed of the Tesla V-100 GPU, so I eventually switched to Notebooks.
The blog post to follow
To get this done, I mostly followed this excellent AWS blog post. It covers in detail all the steps needed to set Docker up in Studio and I kept getting back there in case of doubt.
What you need
- Install
sagemaker-studio-image-build(here). You will need it to build your image, tag it and automatically push it to ECR. - An IAM role with specific privileges (and a trust policy) to grant the services involved in the pipeline to interact with each other. Look for Prerequisites in the aforementioned post.
- A valid
Dockerfile. - A
create.shscript to register the newly uploaded Docker image to SageMaker Studio. - A
app-image-config-input.jsonand adefault-user-settings.jsoncontaining relevant settings and both invoked bycreate.sh.
Here the files I used.
# Dockerfile
FROM python:3.8
RUN apt-get update
RUN apt-get install -y git
RUN pip install --upgrade pip
RUN pip install ipykernel && \
python -m ipykernel install --sys-prefix && \
pip install --quiet --no-cache-dir \
'boto3>1.0<2.0' \
'sagemaker>2.0<3.0'
RUN apt-get install -y gcc
RUN pip install icevision[all] icedata
RUN pip install ipywidgets
RUN jupyter nbextension enable --py widgetsnbextensionOnce you write your Dockerfile, before doing anything else, it is always very important to check if it works as expected. Build it and run a container on top of it, to check if all the libraries you intended to be present are actually there. Here how do it:
# navigate to the folder where the Dockerfile is located
docker build -t icedev .
# and then
docker run -t -i --name=test --rm icedev bash
# if everything works out you, are now inside the container.
# type "python" and try importing the libraries you installedSome more files:
# default-user-settings.json
{
"DefaultUserSettings": {
"KernelGatewayAppSettings": {
"CustomImages": [
{
"ImageName": "icedev",
"AppImageConfigName": "custom-icedev"
}
]
}
}
}In the `app-image-config-input.json` file, you need to ensure that the Uid, Gid, and the kernel name matches the kernelspecs and user information in the Docker image. To extract these values, refer to this document.
# app-image-config-input.json
{
"AppImageConfigName": "custom-icedev",
KernelGatewayImageConfig": {
"KernelSpecs": [
{
"Name": "python3",
"DisplayName": "Python 3"
}
],
"FileSystemConfig": {
"MountPath": "/root/data",
"DefaultUid": 0,
"DefaultGid": 0
}
}
}# create.sh
ACCOUNT_ID=<your aws="" account="" id=""># Replace with your AWS account ID
REGION=<your region=""> #Replace with your region
DOMAINID=<your sagemaker="" studio="" id=""> #Replace with your SageMaker Studio domain name.
IMAGE_NAME=icedev #Replace with your Image name
# Using with SageMaker Studio
## Create SageMaker Image with the image in ECR (modify image name as required)
ROLE_ARN='<the arn="" of="" the="" iam="" role="" you="" created="" before="">'
aws --region ${REGION} sagemaker create-image \
--image-name ${IMAGE_NAME} \
--role-arn ${ROLE_ARN}
aws --region ${REGION} sagemaker create-image-version \
--image-name ${IMAGE_NAME} \
--base-image "${ACCOUNT_ID}.dkr.ecr.${REGION}.amazonaws.com/smstudio-custom:${IMAGE_NAME}"
## Create AppImageConfig for this image (modify AppImageConfigName and KernelSpecs in app-image-config-input.json as needed)
aws --region ${REGION} sagemaker create-app-image-config --cli-input-json file://app-image-config-input.json
## Update the Domain, providing the Image and AppImageConfig
aws --region ${REGION} sagemaker update-domain --domain-id ${DOMAINID} --cli-input-json file://default-user-settings.json</the></your></your></your>How to do it
The hard part is covered. Now what is left is executing scripts. Navigate to the folder where all the previously created files are located and enter the following in a terminal.
# builds image and pushes to ECR
sm-docker build . --repository smstudio-custom:icedev
# attaches ECR image to SageMaker Studio
chmod +x create.sh
./create.shAfter running the `sm-docker` command, go to the ECR AWS console and you should see a new image popping up under the smstudio-custom repository (icedev in my case).

After that, once the `create.sh` runs successfully, you can land on the SageMaker Studio console and check if the image was attached to your domain. In the below screenshot you can see that the icedev Docker image was indeed correctly added.

The last step left is to check if what we put together works. To do that, open Studio, fire up a notebook and select a kernel. In the drop-down menu, you should see the `icevision:latest`environment we just added. Click on it, add compute by picking the EC2 machine suiting your needs, and try importing the libraries installed as part of the Docker image. If everything goes as expected, the below screenshot should look familiar to you.

Thanks for reading this far! I hope you enjoyed it and found it useful.


