
Note: Jupyter notebook with TabNet experiments on the PetFinder dataset. Original Tensorflow implementation of TabNet by Google. PyTorch version (which I ended up using) by DreamQuark.
Introduction
As mentioned in this previous post, one way to step up my PetFinder experiments is, among others, to test fancier model architectures. When it comes to tabular data, an appealing candidate is the very recent TabNet, proposed by Google researchers in Feb 2020. Let’s see what this is about.
The first step I took was to go through the paper. I did not want to over-complicate things, so I carefully read up until the architectural part (section 3 included), skimming over the rest of the content. Specifically, I didn’t dig into the interpretability section of the work, which is arguably something I might want to get back to, at a later time. The architecture is not complicated per-se: nevertheless, there are lots of moving parts and it took me quite some effort to completely clear it up, which I eventually managed to do only by reading, and manually playing around with the DreamQuark’s PyTorch implementation of the paper (the one I ended up using in my experiments).
The purpose of this post is to report on what I have discovered along the way; open the TabNet’s box and illustrate what is happening inside. I have always found visual representations of models the best way to fully understand their inner workings, so I will try to cut down the words and let pictures play the dominant role. I hope you will find them as convincing as I did!
PetFinder
Before moving on, though, it is worth spending a couple of sentences on what motivated me to dive into TabNet in the first place: try to improve on my previous PetFinder experiments. The model to beat was a fine-tuned CatBoost built on top of a curated set of features, which achieved 0.38 Quadratic Weighted Kappa (QWK). Cutting it short, TabNet came not even close to that. It actually performed significantly worse than my first RandomForest baseline, and worse than my latest Deep Learning attempts. The maximum I could squeeze out of it was an embarrassing 0.23 QWK, obtained on the same set of CatBoost’s features, after manually tweaking hyperparameters for quite some time. Almost hopeless. I am not sure what drove such poor results: no matter the direction I stretched my tuning, I could not move the needle by any significant amount. Given the performance claimed on standard benchmarks by the paper’s authors, I think there is a lot of potential in this architecture, so I am glad I added it to my toolbox anyway. I might have more luck on another dataset.
Now, let’s move to the fun part.
TabNet
Visualization conventions
First, a quick clarification around the drawing convention in the upcoming visualizations.
Tensors
- are represented in rectangular grey checkerboards.
- the shape is always specified in brackets, with the batch size (BS) dimension sometimes skipped to save space or avoid crowding up the slide.
- the name is added only if needed to make referencing easier. If that happens it is rendered in bold prior to the shape.
- for instance, in Figure 1, the 4 represented tensors have all the same shape. The first 2 are named
.
Single mathematical operations are signaled with white circles. For the sake of clarity, in Figure 1, the leftmost circle translates into “gamma minus the tensor connected to it”, whereas the rightmost one “multiplies two tensors”.
Entire network’s layers or steps involving more than one mathematical calculation are displayed as colored rectangles. If not strictly evident, with ReLU being an example of such cases, those rectangles are expanded in dedicated diagrams to uncover their inner workings.

: Batch Size
: shape of the input dataset, e.g. number of features passed to the model.
: size of the decision layer, e.g.
features are mapped to
(where
) in Fully Connected (FC) layers. More details in the below relevant section.
: size of the attention bottleneck, e.g.
(where
) and then to
GLU layer
The first building block of TabNet is the Gated Linear Unit layer, named after the GLU non-linearity being one of its components. The GLU layer takes a tensor of size 
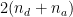

Feature Transformer
The GLU layer is the main component of the second building block of TabNet: the Feature Transformer (FT). This block is made of 4 GLU layers: the first 2 are shared across the entire network, e.g. the weights of their underlying FCs are initialized only once, and any future FT block will share the same. The last 2 are instead different for each FT, allowing for more modeling flexibility. As you can see from Figure 3, the key insight from this block is that GLU layers are concatenated with each other, in a ResNet style, after being multiplied by a constant scaling factor.

Attentive Transformer
Keeping on with TabNet’s foundations, the next brick is the Attentive Transformer (AT). The purpose of this block is to add an attention mechanism to the network, by forcing sparsity into the feature set and learning to focus on specific variables only. The learning part is taken care of by an FC layer which expands a tensor of size 

Decision Step
Now that we have the Feature and Attentive Transformers defined, we can start putting things together into a Decision Step (DS). As we will see, TabNet’s core idea lays in stacking subsequent DSs one after the other, so let’s start looking into one of those. Figure 5 shows the first step of the chain. The architecture within the blue dashed rectangle is the actual DS, e.g. what gets repeated, whereas the outside is either raw data preprocessing (left – done once at the beginning) or matrices initialization (top).
- Raw tabular data (
.
- which is split in 2 chunks;
,
.
.
.
- As you can see from the diagram, 4 elements are passed to the next DS:
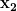

Putting it all together
Once figured one Decision Step out, it is easy to visualize what TabNet is all about. Figure 6 schematically shows the entire architecture, putting together all the previous sections. As you can see, at the end of 


Loss function: sparsity regularization
Last but not least, it is worth spending a few lines on the regularization term the TabNet authors propose for the loss function. Quoted from the paper:
To further control the sparsity of the selected features, we propose sparsity regularization in the form of entropy

I turned the previous ugly equation into Figure 7. The un-regularized loss is the standard Cross-Entropy or MSE for classification and regression respectively. The regularization factor instead, as you can see, is just a mathematical aggregation of the 

Happy learning!



Comments are closed.